Chapter 5 Processing Collected Quantitative Data for Easy Analysis Input
5.1 Introduction
Within interdisciplinary or highly collaborative research groups, quantitative data collected by one subgroup may require analysis by another subgroup. In seeking efficiency and internal logic, the subgroup collecting the data may collect and record the data in a manner that does not facilitate subsequent data analysis.
For example, data about agricultural production is commonly collected in an order related to its location in the field, e.g. moving from one agricultural plot to an adjacent agricultural plot. While collecting agricultural production data in this way is less time consuming, it does not commonly lead to a set of data amenable for immediate data analysis. Thus processing collected quantitative data from one subgroup such that data analysis is easier for another subgroup is commonly needed.
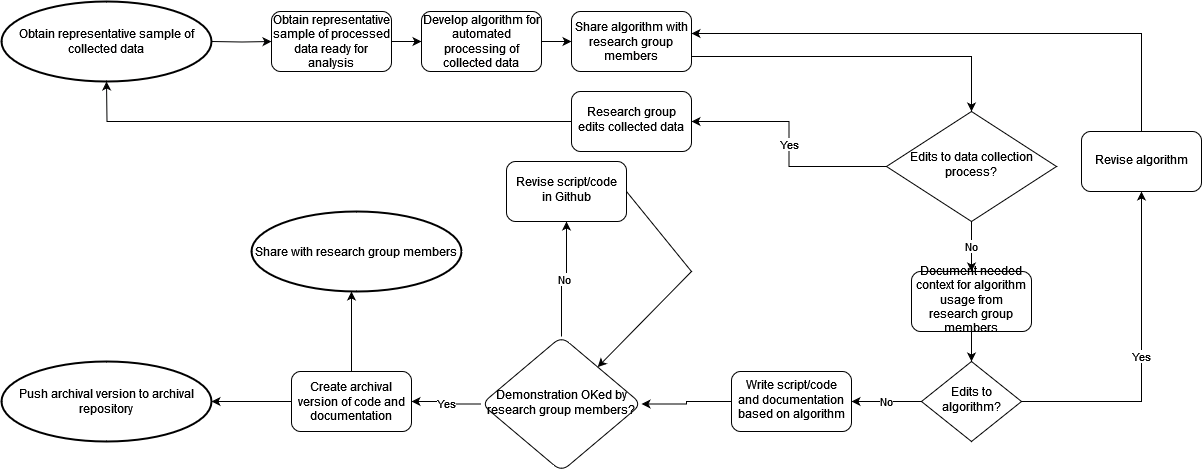
Here we present general steps (including a diagram), guidelines, and references for automating processing of collected quantitative data from one subgroup such that data analysis by another subgroup is eased. Vital to creating a successful process to transform collected data for easy analysis input is obtaining appropriate context from the data collection and data analysis subgroups. To make this process modular and extensible for future data collection, good software engineering and documentation practices are also important.
5.3 Detailed Steps
These steps are written as if the person automating the processing of collected quantitative data for analysis input is not associated with either data collection or data analysis. If they are associated with either, steps for which they already have the appropriate content or context can be skipped.
- Obtain from the research group a representative sample of collected data, including information on how the data was collected and why it was collected that way (i.e., its metadata).
- “Representative” in this case means that the sample of collected data and metadata is sufficient to fully understand the data collection process and the nature and structure of the data.
- Ask the data collection subgroup about the number of records in the collected dataset to ensure the planned algorithm is appropriate for pre-processing this size of data.
- Confirm that the data collection process will be similar in the future; otherwise developing an automated process may not be as beneficial.
- Obtain from the research group a representative sample of processed data ready for input into the analysis application, including what analysis application and input data structure will be used.
- “Representative” here means that the sample of processed data, including metadata, is sufficient to fully understand the data processing procedure.
- Develop algorithm to pre-process and document preprocessing workflow for case study.
- Share diagram or example of algorithm with subgroup representatives for their review, editing and ultimate approval.
- With input from subgroup representatives, may determine that data collection process could/should change, or that preprocessing output should be altered. Could be an iterative process.
- Ask each subgroup representative what context is required for both sub-groups to understand how preprocessing data for analysis input is to be done (and also for the use of a wider community) Include this context in algorithm for later documentation.
- Recommend output of data for analysis input to be in open formats (e.g. csv).
- Develop script/code to execute agreed-upon algorithm.
- See if packages available from frictionlessdata or other already existing functions will support this pre-processing.
- Use programming/scripting language that is familiar to subgroup representatives.
- Script/program documents provenance of pre-processing workflow (possibly in a log file) for improved data re-use.
- Incorporate best practices of working with data (e.g., keeping raw data intact, using code commenting, assertions).
- Documentation for the code should include:
- Information on how data was collected by that particular subgroup.
- Context agreed upon by subgroup representatives to understand data processing.
- Format of data after preprocessing, and its use in data analysis by that particular subgroup.
- Other software documentation information according to best practices (e.g., description of dependencies).
- See Data Curation Network primers for specific languages/applications.
Demonstrate script/code to research group members, revise as necessary.
Add appropriate open-source license to the code and its documentation.
Place a copy of the script, code, and documentation in a publicly accessible location for further development. One should also be placed in an archival repository.